






La generación de imágenes con inteligencia artificial ha vivido su gran revolución de la mano de modelos como Stable Diffusion, DALL-E o Midjourney. Sin embargo, todos ellos comparten un denominador común: o son modelos propietarios con acceso limitado, o son open-source con limitaciones importantes en el renderizado de texto y la coherencia semántica. GLM-Image, lanzado por la empresa china Z.AI en enero de 2026, llega a cambiar esta ecuación.
Con 16 mil millones de parámetros y una arquitectura híbrida que combina un módulo autorregresivo con un decodificador de difusión, GLM-Image se posiciona como el primer modelo de generación de imágenes open-source de grado industrial. Es decir, un modelo que no solo es gratuito y modificable, sino que compite directamente con las alternativas propietarias en calidad y capacidad — especialmente en las categorías donde históricamente los modelos abiertos fallaban: el renderizado preciso de texto y la generación de imágenes con alto contenido semántico.
En un contexto donde la IA generativa se está convirtiendo en infraestructura básica para la industria creativa, tener acceso a un modelo de esta potencia sin restricciones de licencia es un cambio de paradigma. Herramientas como Marble de World Labs también están redefiniendo las posibilidades de la generación de contenido visual con IA, aunque desde un enfoque muy diferente.
🔍 ¿Qué es GLM-Image y qué problema resuelve?
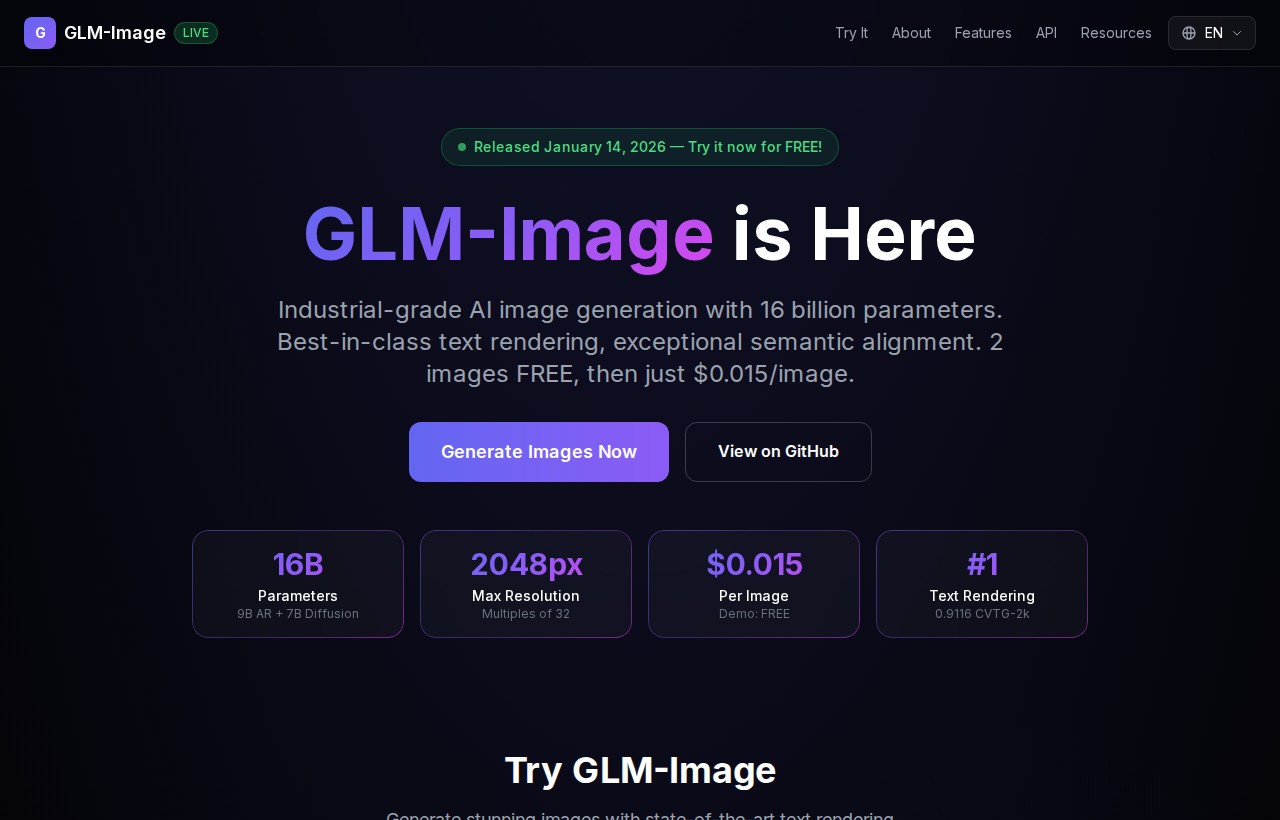
GLM-Image es un modelo de generación de imágenes desarrollado por Z.AI (anteriormente Zhipu AI), una empresa china de inteligencia artificial fundada en 2019 como spinoff de la Universidad de Tsinghua. El modelo fue lanzado el 14 de enero de 2026 y está disponible tanto como modelo open-source en GitHub y Hugging Face como a través de la API de Z.AI.
El problema central que resuelve GLM-Image es la brecha histórica entre calidad y accesibilidad en la generación de imágenes con IA. Según Wikipedia, la IA generativa moderna se basa en arquitecturas transformer y técnicas de difusión que permiten generar contenido visual de alta calidad. Sin embargo, los mejores modelos de difusión puros como Stable Diffusion tienen dificultades con el renderizado preciso de texto dentro de las imágenes — un problema crítico para aplicaciones como pósters, presentaciones o material de marketing. GLM-Image soluciona esto integrando comprensión semántica global (vía el módulo autorregresivo) con alta fidelidad visual (vía el decodificador de difusión).
⚙️ Características principales
Arquitectura híbrida AR+Difusión de 16B parámetros. GLM-Image combina un módulo autorregresivo de 9B parámetros (basado en GLM-4-9B-041) con un decodificador de difusión de 7B parámetros que sigue la arquitectura CogView4. Esta combinación permite planificar la composición global de la imagen con precisión semántica y luego renderizarla con alta fidelidad visual — algo que los modelos puramente de difusión no pueden lograr con la misma consistencia.
Renderizado de texto líder del mercado. Una de las debilidades históricas de los generadores de imágenes con IA ha sido la incapacidad de renderizar texto de forma legible y precisa dentro de las imágenes. GLM-Image destaca aquí, superando a modelos como Google Nano Banana Pro en pruebas de renderizado complejo de texto. Es especialmente efectivo para pósters, infografías, presentaciones y material científico, incluyendo texto en chino.
Generación y edición en un único modelo. A diferencia de muchos modelos que solo generan imágenes a partir de texto, GLM-Image soporta texto a imagen e imagen a imagen en el mismo sistema, incluyendo edición, transferencia de estilo, generación preservando la identidad del sujeto y consistencia entre múltiples sujetos. Esto elimina la necesidad de diferentes modelos para distintas tareas.
Open-source completo bajo licencia MIT. El código fuente y los pesos del modelo están disponibles en GitHub (github.com/zai-org/GLM-Image) y Hugging Face. La licencia MIT permite uso comercial, modificación y distribución sin restricciones, lo que lo hace ideal tanto para proyectos individuales como para integraciones empresariales.
API con precios competitivos. Para quienes prefieren no ejecutar el modelo localmente, Z.AI ofrece acceso vía API con dos imágenes gratuitas y luego 0,015 $ por imagen generada — considerablemente más económico que las alternativas propietarias como DALL-E 3 o Midjourney.
💰 Precio y planes
GLM-Image tiene una estructura de precios dual. Por un lado, el modelo open-source es completamente gratuito: puedes descargarlo de GitHub o Hugging Face y ejecutarlo en tu propia infraestructura sin coste. La única limitación es el hardware necesario (se recomienda GPU de alto rendimiento por los 16B de parámetros). Por otro lado, la API de Z.AI ofrece las primeras 2 imágenes gratis y luego cobra 0,015 $ por imagen generada — sin suscripciones ni compromisos mínimos. Para contexto: Midjourney cuesta a partir de 10 $/mes con generaciones limitadas, mientras que DALL-E 3 cobra en función de resolución y calidad.
✅ Análisis: Pros y Contras
| ✅ Ventajas | ❌ Desventajas |
|---|---|
| Mejor renderizado de texto en imágenes del mercado open-source | Requiere hardware potente para ejecutarlo localmente (16B params) |
| Open-source bajo licencia MIT: uso comercial sin restricciones | La resolución de salida debe ser divisible por 32 |
| Combina generación y edición en un único modelo | Con prompts complejos puede no cumplir todas las instrucciones |
| API con precio muy competitivo (0,015$/imagen) | El demo en Hugging Face puede ser lento en horas pico |
| Excelente para pósters, presentaciones y material científico | La estética general es ligeramente inferior a Midjourney top tier |
⭐ Puntuación oledir.com: 4.0/5
Puntuación: 4.0/5 — GLM-Image es la mejor opción open-source de generación de imágenes con IA en 2026, especialmente para aplicaciones que requieren texto preciso dentro de las imágenes. Su arquitectura híbrida resuelve problemas que han persistido en el sector desde el inicio de la generación con IA.
- 🎯 Facilidad de uso: 3.5/5
- 💡 Funcionalidades: 4.5/5
- 💰 Relación calidad-precio: 5.0/5
- 🔧 Integraciones: 3.8/5
- 📞 Soporte: 3.2/5
🚀 ¿Para quién es ideal GLM-Image?
GLM-Image está especialmente indicado para desarrolladores e investigadores que buscan un modelo de generación de imágenes potente sin restricciones de licencia. También es ideal para diseñadores y creadores de contenido que necesitan generar material visual con texto integrado — pósters, portadas, presentaciones — donde otros modelos fallan. Las empresas tecnológicas que quieren integrar generación de imágenes en sus productos sin depender de APIs propietarias encontrarán en GLM-Image la solución más flexible y económica. Por su excelente soporte para el idioma chino, es también la primera opción para proyectos orientados al mercado asiático.
🔗 Prueba GLM-Image gratis
👉 Visita GLM-Image — Sitio oficial
